
The idea of using algorithms and creativity together is always highly debated. On one hand, creativity is normally seen as an inherently human trait, one that comes from “within” the human mind and soul. On the other hand, certain genres are known to approach music very systematically, almost formula-like in their strategy to make a hit. Two prime examples of this are Pop and Country, where it's theorized that major labels sit down and formulate songs from chords to lyrics, in order to guarantee a money maker. With these two camps of thought, we have a tale of two questions; first, is it true that the most popular songs of a given genre follow some sort of pattern, and second, are these patterns significant enough to build a model to predict the success of new songs, and whether these models have some consistencies access genres.
To approach this problem, we relied on the Million Song Dataset, a freely-available collection of audio features and metadata for a million contemporary popular music tracks. This dataset contains metadata such as danceability, song duration, temp, key and time signature. The dataset also includes information about the artist and album, such as artist location, familiarity, and album release id.
The initial approach was to take each song from the MSD, grab additional metadata using the Spotify API, group by genre, then try to run Decision Tree and Regression classifiers on each set of songs to see whether patterns emerged. While ambitious, the data collection became too difficult to manage due to inconsistencies between APIs and rate limits, so in the end we settled on just trying to predict song popularity across all songs in a subset (1%) of the MSD. In this case, popularity is measured by the “song.hotttnesss” index supplied by the dataset. This feature is a value from 0 to 1 that describes how popular the given song is.
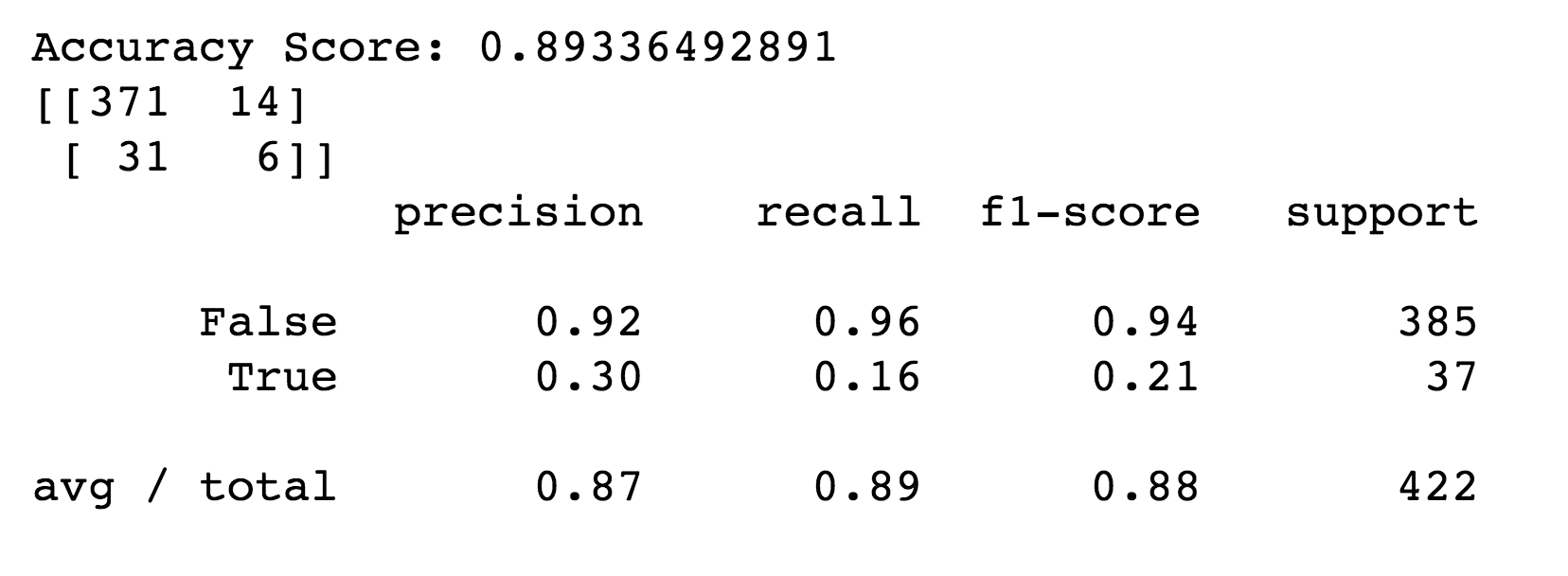
In the end our Decision Tree Classifier was able to predict whether a song would be in the top quartile of popularity with 89% accuracy, and our Decision Tree Regressor predicted our training set of song’s popularity with a MSE of 0.02. The most important features were a song's "familiarity", year released, and things like being in a major key or written by an already popular artist.