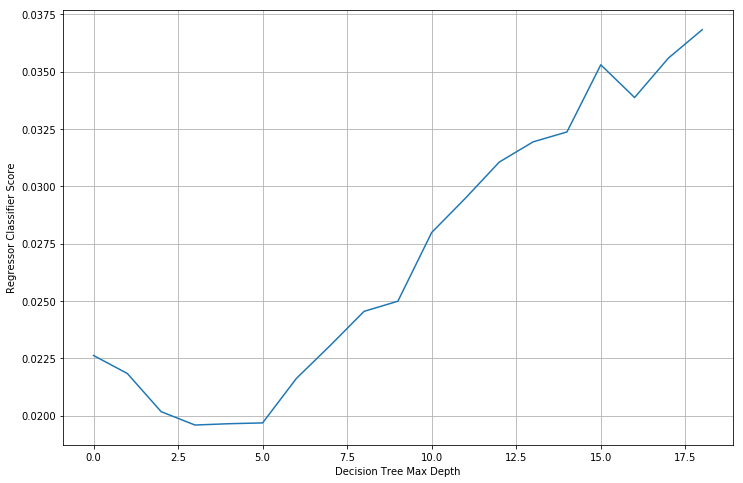
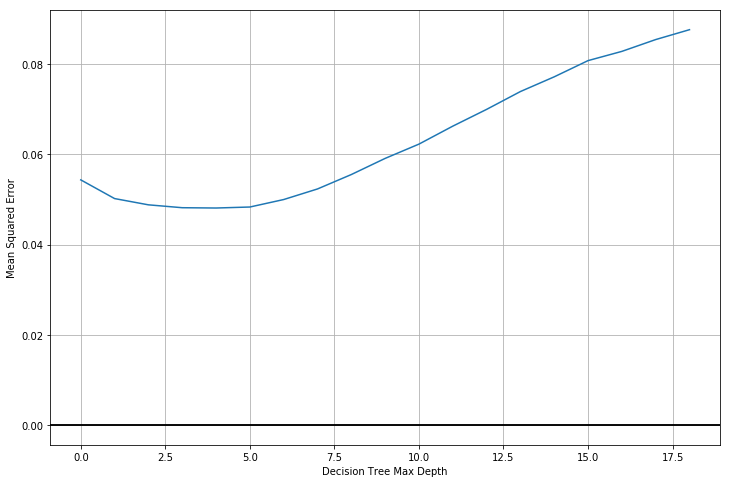
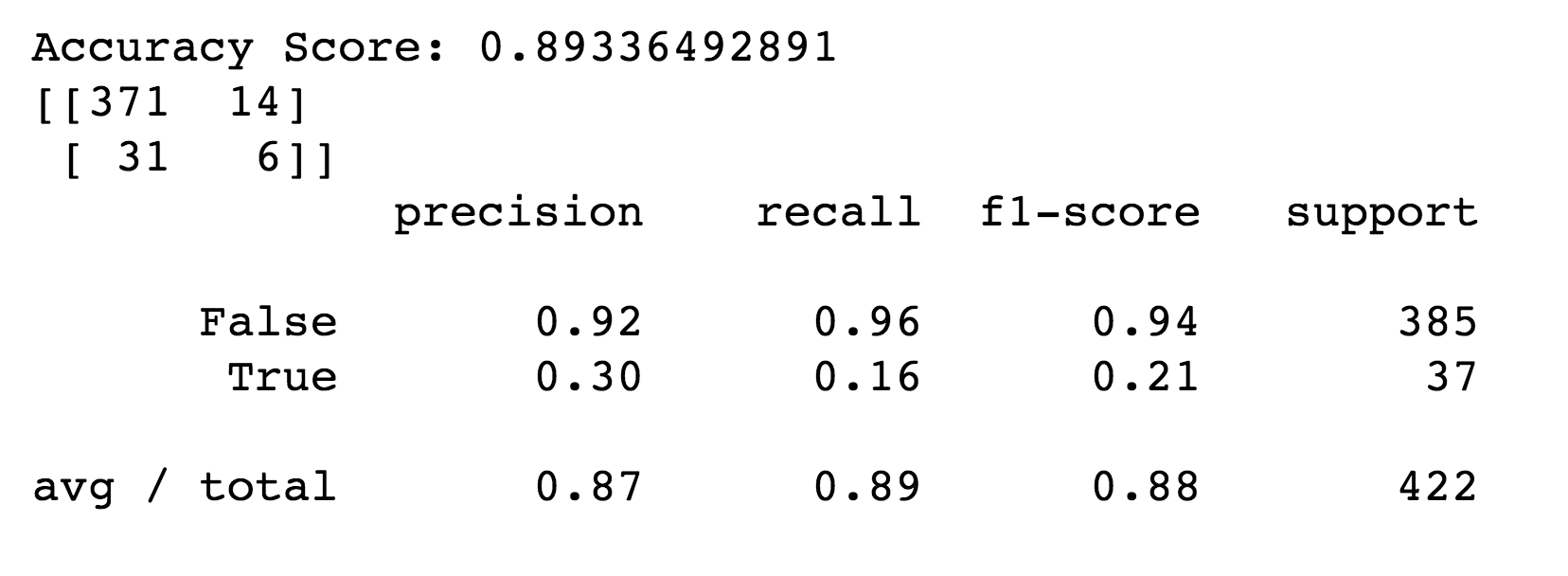
Detailed Report
The idea of using algorithms and creativity together is always highly debated. On one hand, creativity is normally seen as an inherently human trait, one that comes from “within” the human mind and soul. On the other hand, certain genres are known to approach music very systematically, almost formula-like in their strategy to make a hit. Two prime examples of this are Pop and Country, where it's theorized that major labels sit down and formulate songs from chords to lyrics, in order to guarantee a money maker. With these two camps of thought, we have a tale of two questions; first, is it true that the most popular songs of a given genre follow some sort of pattern, and second, are these patterns significant enough to build a model to predict the success of new songs, and whether these models have some consistencies access genres.